Programmatic SEO That Ranks After the 2026 Spam Update
Most programmatic pages got deindexed this spring. The ones that rank at scale share one trait: each page is the database, not a description of one.

- Google's March 2026 spam update finished in under 20 hours and stripped 60% to 90% of rankings from sites running thin programmatic pages. Volume without unique data was the kill criterion.
- The pattern that survives: the page is the database, not a description of one. Wise runs 8.5 million currency converter pages because each one shows live, real data nobody else has.
- Proprietary data per page is the only durable moat. If a competitor can regenerate your page from the same public inputs, it is a doorway page and it will eventually be deindexed.
- Scale is a graph problem, not a publishing problem. Hub, spoke, and crosslink structure is what lets 10,000 pages each earn the right to rank.
- The punishable pattern is precise: many pages, one template, swapped keywords, no unique value per page. Hit one genuine data point per page or do not ship the page.
Programmatic SEO did not die in March 2026. The lazy version of it did, and it died fast.
On March 24, 2026, Google's spam update rolled out, ran SpamBrain across the index, and completed in under 20 hours. Sites that had generated thousands of near-identical pages by swapping a keyword into a template lost 60% to 90% of their rankings almost overnight. The follow-on core update later that spring finished the job on anything that survived the first pass. If your programmatic strategy was "one template times ten thousand keywords," it is gone, and it is not coming back.
But Wise still ranks for 8.5 million currency conversion pages. Zapier still owns the long tail of app-integration queries. G2 still dominates software comparison. These are programmatic pages at massive scale, and they did not get touched, because they were built on a fundamentally different pattern. This is that pattern, and it is the spec we build to inside programmatic pages engagements.
What actually got punished
Be precise about the kill criterion, because the misunderstanding is what gets sites penalized. Google did not penalize programmatic pages for being programmatic. It penalized them for being thin. The technical name in Google's guidelines is scaled content abuse: producing many pages primarily to manipulate ranking, with little unique value on each. The tell is a doorway page, a page that exists only to capture a keyword and funnel the visitor somewhere else, offering nothing the visitor could not get from any of its thousand siblings.
Run the substitution test on your own pages. Take any one programmatic page, mentally swap its target keyword for a sibling's, and ask what changes. If only the keyword in the heading and the meta description change, and the body is the same boilerplate with a find-and-replace, it is a doorway page. The engine can see the template just as clearly as you can. The fact that you generated 10,000 of them is not the crime. The fact that none of them carries unique value is.
The pattern that survives: the page IS the database
Here is the single most important mental model in programmatic SEO, and it is the line between the survivors and the deindexed. A page that ranks is the database, not a description of one. The page does not talk about data. It presents the data itself, structured, specific, and unavailable in that form anywhere else.
Look at what the survivors actually put on each page. A Wise currency page shows the live mid-market rate, the historical chart, today's movement, and the real cost versus a bank, all of it live and computed. A Zapier integration page shows the actual triggers and actions available between two specific apps, pulled from Zapier's own connection graph that no competitor can replicate. A G2 category page shows real, current user reviews and ratings nobody else holds. In every case, the value the visitor came for is on the page, and the page is the only place that exact rendering of the data exists.

If your page describes a database, you built a doorway. If your page is the database, you built an asset. The difference is whether the visitor's answer lives on the page or somewhere you are pointing them to.
Shivam Bindal
This reframes the whole build. You are not writing 10,000 articles. You are building one data application that happens to render 10,000 public, indexable views, each one a genuinely useful answer to a specific query. The content is the data. The template is just the frame around it.
Unique proprietary data is the only moat
Every durable programmatic footprint sits on data a competitor cannot regenerate from the same public inputs. That is the entire moat, and it is worth being ruthless about. Ask one question of any page you plan to ship: could a competitor recreate this exact page using only public information and a few hours? If yes, you have no moat, and the page is one algorithm update away from being deindexed along with everyone else's version of it.
Proprietary data comes from a small number of real sources, and you need at least one of them before you scale anything.
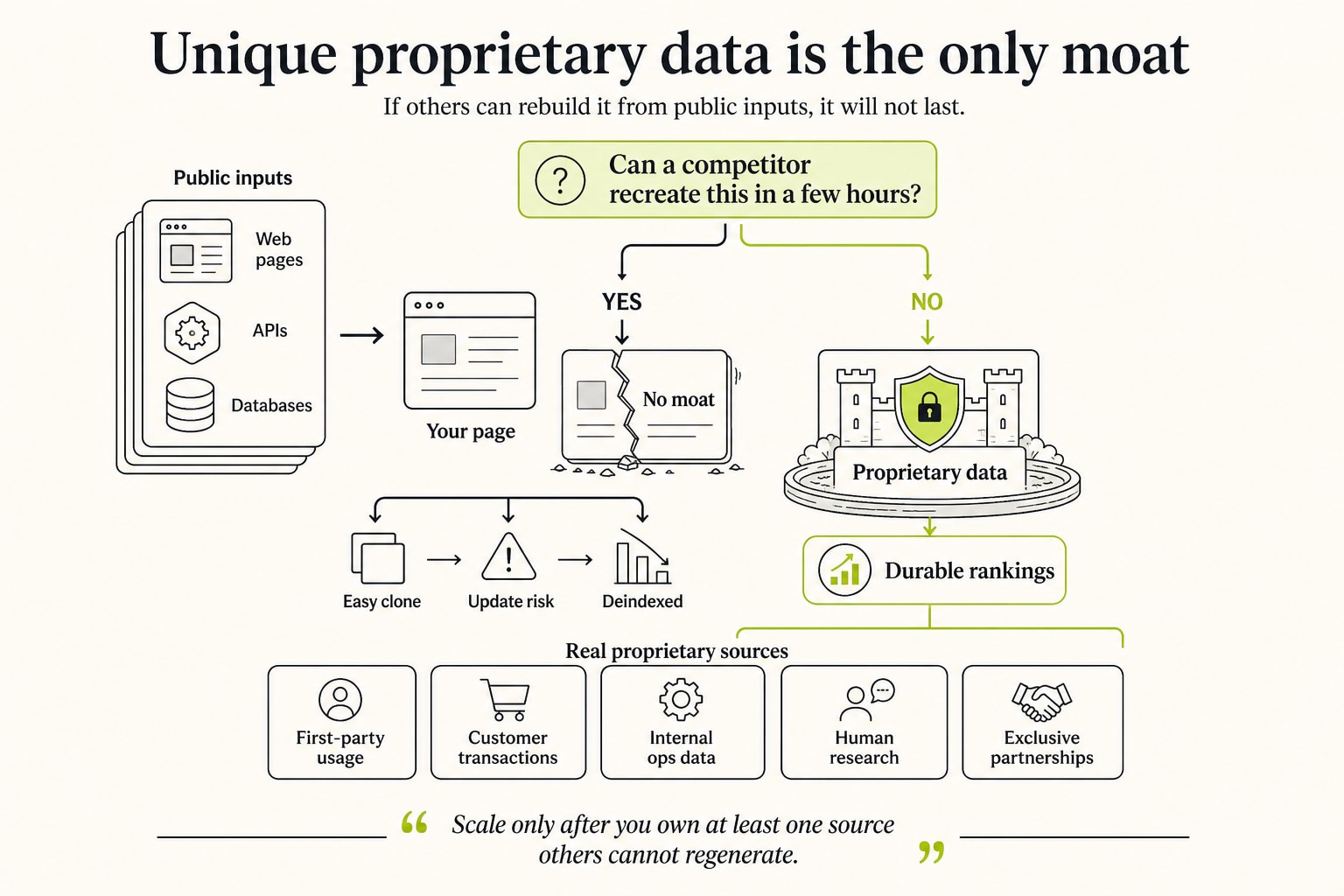
- First-party product data: Zapier's integration graph, a project-management tool's template library, an API's endpoint catalog. Data your product generates that nobody else has.
- Live computed data: Wise's real-time rates, a logistics tool's live transit estimates. Numbers that are correct only because you compute them fresh.
- Aggregated user data: G2's reviews, a marketplace's pricing and availability. Volume of real human input you have collected and competitors have not.
- Original collected data: structured datasets you build by scraping, surveying, or measuring at scale, then clean and present per page.
If you do not own first-party or computed data, the fourth path is the one most B2B SaaS companies can actually execute. You build the proprietary dataset by collecting it. We run that collection through a data scraping layer, gathering, cleaning, and enriching structured data at scale, so each page has a genuine, defensible fact set behind it instead of spun prose. The dataset is the product. The pages are how search finds it.
We build the dataset first, then the page graph, so every page earns its own ranking.
Scale is a graph problem: hub, spoke, and crosslink
Ten thousand pages with no internal structure is not a content asset. It is a flat field of orphans the crawler struggles to reach and the engine struggles to understand. The survivors organize their pages into a deliberate graph, and the graph is what distributes authority and crawl budget to the deep long tail.
- 01Hubs
A small number of high-authority category pages that explain the space, link out to the spokes, and earn the bulk of your external links. The hub is where backlinks and brand mentions land and from which authority flows down.
- 02Spokes
The programmatic pages themselves, one per specific entity, query, or data slice. Each spoke is the database view for its target and links up to its hub and laterally to its closest siblings.
- 03Crosslinks
Lateral links between related spokes, a currency page to its inverse pair, an integration page to the other integrations for the same app. Crosslinks model the real relationships in your data and keep both crawlers and users moving through the graph.
The crosslink layer is what most teams skip and what most distinguishes a graph from a dump. Done well, it means a deep spoke that no external site links to is still two clicks from a hub and surrounded by relevant neighbors, which is exactly what gives it the standing to rank. Plan the graph from the data model before you generate a single page, because the relationships in your data are the relationships in your link structure.
How to scale 10,000 pages that each deserve to rank
Volume is still the point. The opportunity in programmatic SEO is capturing thousands of specific, low-competition queries that no human content team could economically write one by one. The discipline is making volume and quality coexist, which means every page clears a real bar before it ships.
- 01Start from the data, not the keyword list. Identify the proprietary dataset first. The pages you can build are whatever the data can genuinely answer, no more.
- 02Define the per-page value bar: at least one unique data point a visitor cannot get elsewhere in this form. If a row in your dataset cannot clear it, do not generate a page for it.
- 03Prune ruthlessly. If you have data for 50,000 entities but only 8,000 have enough unique data to be useful, ship 8,000. The 42,000 thin pages would drag the whole domain down.
- 04Template the frame, not the substance. The layout repeats; the data, computed numbers, and per-entity specifics do not. Add structured intro copy that summarizes that page's actual data, not generic boilerplate.
- 05Ship JSON-LD schema per page so the structured data is machine-readable, which also drives AI citation, the bridge to SEO and GEO.
- 06Layer a thin band of human or expert review on top, especially on hub pages. Sites that published at scale with zero human review were the first to lose visibility.
Keep the dataset fresh, because stale data is its own quality problem and a refresh signal that engines reward. Pair the per-page data with supporting editorial from your blog pipeline on the hub level, where genuine analysis and original commentary earn the external links that flow authority down into the spokes. The programmatic graph and the editorial layer are not separate projects. They feed each other, the way every channel does inside the B2B SaaS growth operating system.
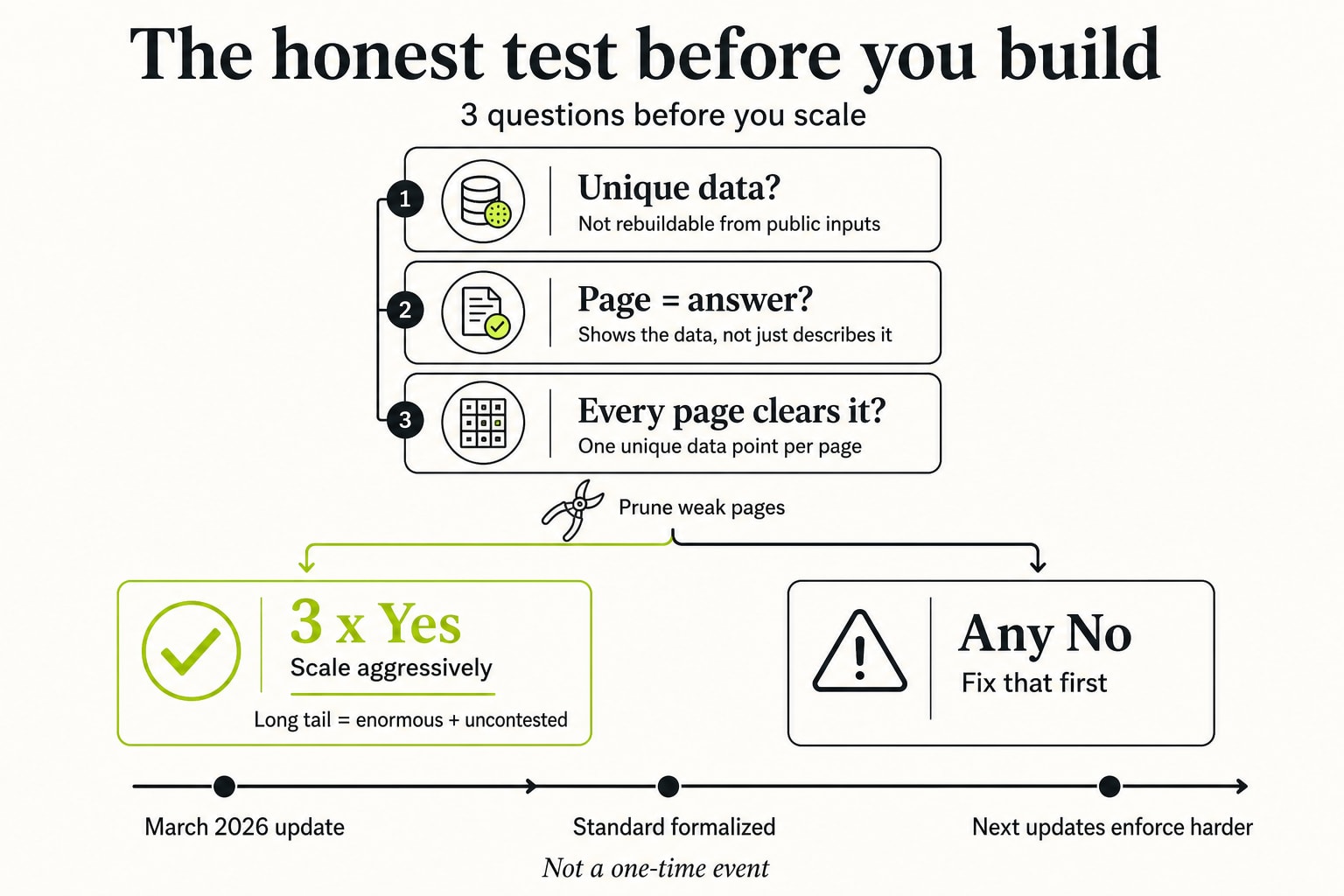
The honest test before you build
Before you generate anything, answer three questions honestly. Do I have data a competitor cannot regenerate from public inputs? Does each page present that data as the answer, rather than describing it and pointing elsewhere? Does every page I plan to ship clear the one-unique-data-point bar, and am I willing to prune the ones that do not? If all three are yes, scale aggressively, because the long tail is enormous and most of it is uncontested. If any is no, fix that first. The March 2026 update was not a one-time event. It was Google formalizing a standard that the next update, and the one after that, will only enforce harder.
Written by Shivam Bindal. Founder, Markingo.
